
Risks and Challenges of Password Hashing
For our readers who are not familiar with what a hash algorithm is, it’s nothing more than a one way function that maps data of variable length to data of fixed length. So if we analyse the above definition we need to understand the following requirements and characteristics of such algorithms:
- One way function: the output cannot be reversed using an efficient algorithm.
- Maps data of variable length to data of fixed length: meaning that the input message space can be infinite, but the output space is not. This has the implication that 2 or more input messages can have the same hash. The smaller the output space, the greater the probability of a collision between two input messages.
md5 has confirmed practical collisions and sha1′s probabilities for reaching a collision are growing every day (more info in collision probability can be found by analysing the classic Birthday Problem), so if we need to apply a hashing algorithm, we should use the ones that have greater output space (and a negligible collision probability), such as sha256, sha512, whirlpool, etc.
They are also called Pseudo-random A functions , meaning that the output of a hashing function should be indistinguishable from a true random number generator (or TRNG).
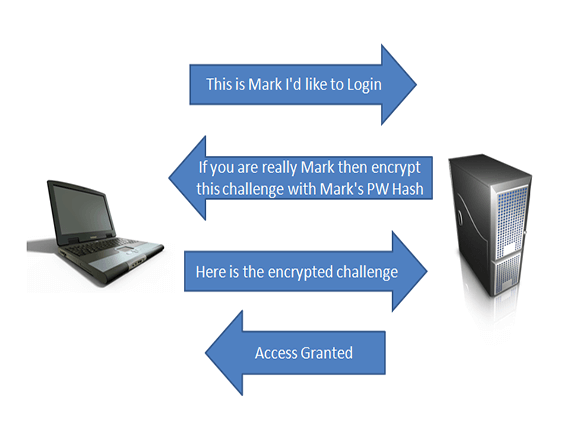
Why simple hashing is insecure for storing passwords
The fact that the output of a hash function cannot be reverted back to the input using an efficient algorithm does not mean that it cannot be cracked. Databases containing hashes of common words and short strings are usually within our reach with a simple google search. Also, common strings can be easily and quickly brute-forced or cracked with a dictionary attack.
Demonstration
Here is a quick video on how a tool like sqlmap can crack passwords via sql injection by bruteforcingmd5 hashes in a database.
Also, we could have just done the simplest of attacks just grab the hash and google it Chances are that the hash exists in an online database. Examples of hash databases are:
We also have to consider that since 2 or more identical passwords will indeed have the same hash value, cracking one hash will automatically give you the passwords of every single user that used the same. Just to be clear, say you have thousands of users, it is very likely that a fair amount of them will use (if passwords policies are not enforced) the infamous 123456 password. The md5 hash value of that password is 10adc3949ba59abbe56e057f20f883, so when you crack this hash (if you even have to) and search for all the users who have this value in their password field, you will know that every single one of them used the 123456 password.
Why salted hashes are insecure for storing passwords
To mitigate this attack, salts became common but obviously are not enough for today’s computing power, especially if the salt string is short, which makes it brute-forceable.
The basic password/salt function is defined as:
f(password, salt) = hash(password + salt)
In order to mitigate a brute-force attack, a salt should be as long as 64 characters, however, in order to authenticate a user later on, the salt must be stored in plain text inside the database, so:
if (hash([provided password] + [stored salt]) == [stored hash]) then user is authenticatedSince every user will have a completely different salt, this also avoids the problem with simple hashes, where we could easily tell if 2 or more users are using the same password; now the hashes will be different. We can also no longer take the password hash directly and try to google it. Also, with a long salt, a brute-force attack is improbable. But, if an attacker gets access to this salt either by an sql injection attack or direct access to the database, a brute-force or dictionary attack becomes probable, especially if your users use common passwords (again, like 123456:
Generate some string or get entry from dictionary
Concatenate with salt
Apply hash algorithm
If generated hash == hash in database then Bingo
else continue iteratingBut even if one password gets cracked, that will not automatically give you the password for every user who might have used it, since no user should have the same stored hash.
The randomness issue
In order to generate a good salt, we should have a good random number generator. If php’s rand()function automatically popped up in your mind, forget it immediately.
There is an excellent article about randomness in random.org. Simply put, a computer can’t think of random data by itself. Computers are said to be deterministic machines, meaning that every single algorithm a computer is able to run, given the exact same input, will always produce the same output.
When a random number is requested to the computer, it typically gets inputs from several sources, like environment variables (date, time, # of bytes read/written, uptime, then apply some calculations on them to produce random data. This is the reason why random data given by an algorithm is calledpseudo random and thus it is important to differentiate from a true random data source. If we are somehow able to recreate the exact conditions present at the moment of the execution of a pseudo-random number generator (or PRNG), we will automatically have the original generated number.
Additionally, if a PRNG is not properly implemented, it is possible to discover patterns in the generated data. If patterns exist, we can predict the outcome Take for instance the case of PHP’s rand()function on Windows as documented here. While it is not clear which PHP or Windows version is used, you can immediately tell there is something wrong by looking at the bitmap generated by usingrand():